Ali Arman — Personal Website — Data Fusion
Across science and engineering, innovation is increasingly driven by sophisticated and expensive data collection technologies. At the same time, vast amounts of already available data remain systematically underexploited. This is often justified by assumed limitations in accuracy, assumptions that are frequently made before the full potential of modern data fusion methods is explored.
Large-scale data streams are generated continuously in transportation systems. Loop detectors, probe vehicles, and other fixed roadside sensors operate daily, at scale, and at low marginal cost. My work in data science and traffic operations is motivated by a simple but powerful premise: the value of existing data can be fundamentally expanded through intelligent fusion, inference, and reconstruction methods.
A central challenge in traffic analysis lies in the reconstruction of vehicle trajectories, particularly when both longitudinal motion and lateral (lane-changing) behavior are of interest. While longitudinal dynamics have been studied extensively, lane-changing maneuvers remain comparatively underexplored. The primary reason is data availability: lane-accurate trajectories are typically obtained through video-based systems, which are expensive, spatially limited, and temporally short-lived. Well-known datasets such as NGSIM and HighD are highly limited in coverage; they provide valuable insights, but at substantial financial and operational cost. Large-scale initiatives like I-24 Motion and DLR-HT provide several hours and kilometers of coverage, but they are even more costly.
In contrast, conventional traffic sensors, especially inductive loop detectors, are deployed ubiquitously and operate continuously. These data sources are traditionally considered insufficient for lane-level trajectory analysis. My data fusion projects demonstrate that this limitation is not inherent to the data itself, but rather to how it is processed. The animation below compares a short list of widely known trajectory datasets with the resulting dataset from my project, TAILOR, highlighting differences in spatial coverage and temporal extent. Beyond these well-known examples, a recent multi-institutional literature mining study (which I contributed to) systematically reviewed and categorized 100+ vehicle trajectory datasets and data collection initiatives.
I introduced two data fusion and large-scale data mining methods that enable the approximation of vehicle trajectories, including lane-changing maneuvers, using conventional roadside sensor data at near-zero additional cost. These methods leverage individual vehicle cross-sectional observations and reconstruct continuous trajectories over extended spatial and temporal horizons.
The resulting dataset and framework, TAILOR, represents a shift from active, infrastructure-heavy data collection toward a passive, scalable, and cost-effective trajectory reconstruction paradigm. As long as individual vehicle detections are available, the approach supports sustained trajectory reconstruction over corridors, networks, and time periods defined by project needs rather than by data collection constraints.
TAILOR enables lane-level behavioral analysis at a scale that was previously impractical, opening new possibilities for traffic safety analysis, operational modeling, and data-driven decision support, without reliance on costly and temporary sensing campaigns.
I developed a data-fusion methodology that turns conventional loop-detector individual vehicle data (IVD) into lane-level trajectory approximations, including inference of lane-changing maneuvers. The motivation is practical: loop detectors permanently monitor most motorways and produce years of data, but those logs are typically treated as “cross-section only” and therefore discarded for lane-change and behavior studies. This work shows that, under realistic detector spacing (on the order of hundreds of meters), that assumption is unnecessarily conservative.
At the core is a probabilistic vehicle re-identification (ReID) engine that matches the same vehicle across successive, lane-specific detector stations by combining three complementary similarity cues, vehicle length, passage time, and passage speed, within a Bayesian likelihood formulation. The method proceeds in two stages: it first locks in extremely reliable lane-keeping matches, then uses those matches as dynamic boundary conditions to recursively resolve the harder cases, including lane changes. This “growth” mechanism is what I refer to as Traffic Flow Crystallization.
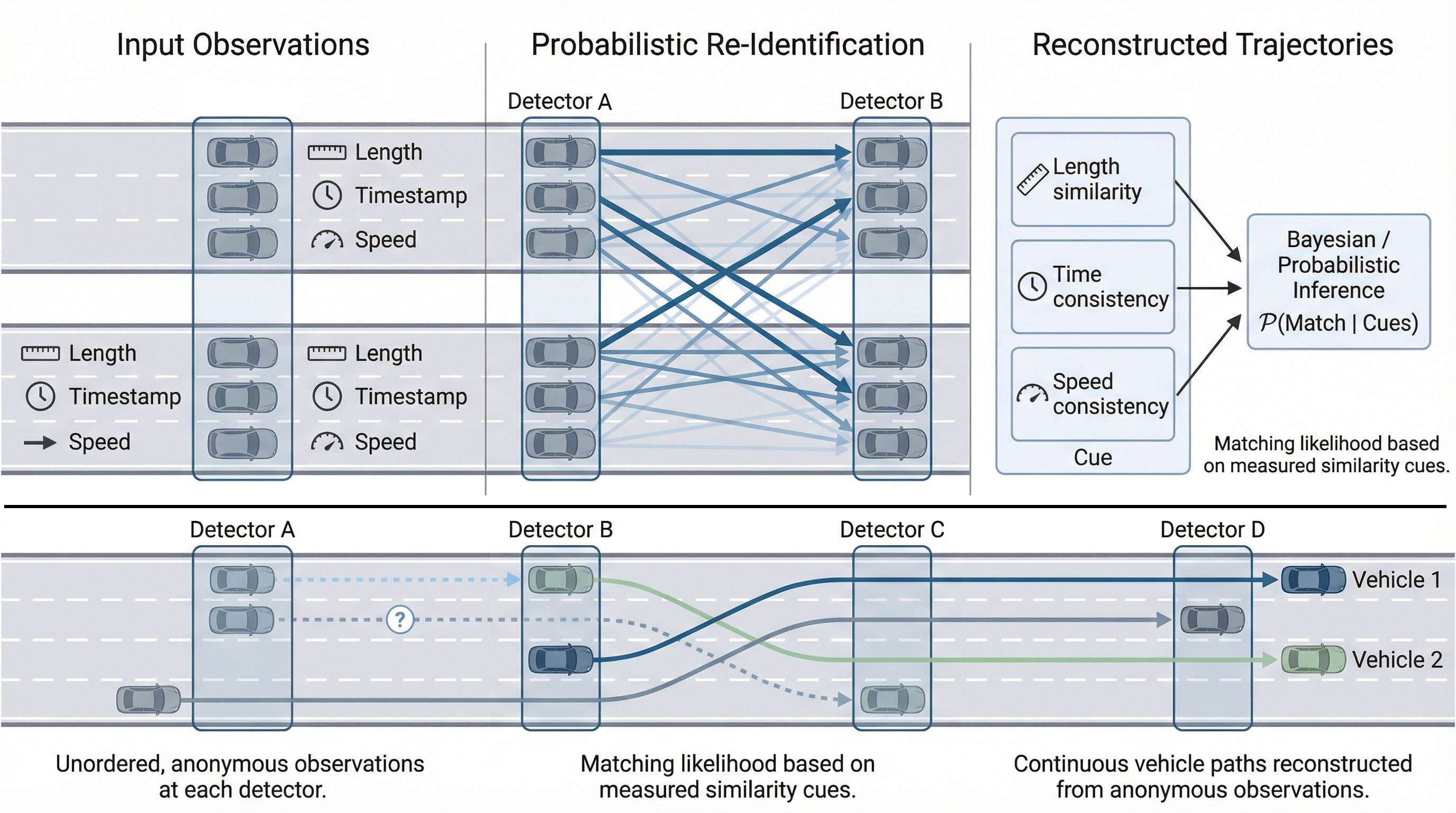
The pipeline produces (I) reconstructed trajectories at a fine temporal resolution and (II) inferred lane changes with an estimated location between detector stations. The results are validated with CCTV-based ground truth for re-identification and lane-change counts, and with centimeter-accurate differential GPS probe trajectories to quantify longitudinal trajectory error and the uncertainty bounds of inferred lane-change locations. In the reported case study, the method achieves >96% vehicle re-identification success (and higher in non-congested conditions) and yields lane-change counts with only a small underestimation relative to ground truth (Transportation Research Board - 2023 & IEEE Transactions on Intelligent Transportation Systems - 2025).
This contribution is not “another dataset,” but a scalable way to convert existing infrastructure into trajectory-like information, enabling lane-change analytics and behavior studies over long corridors and long time periods without relying on expensive camera deployments.
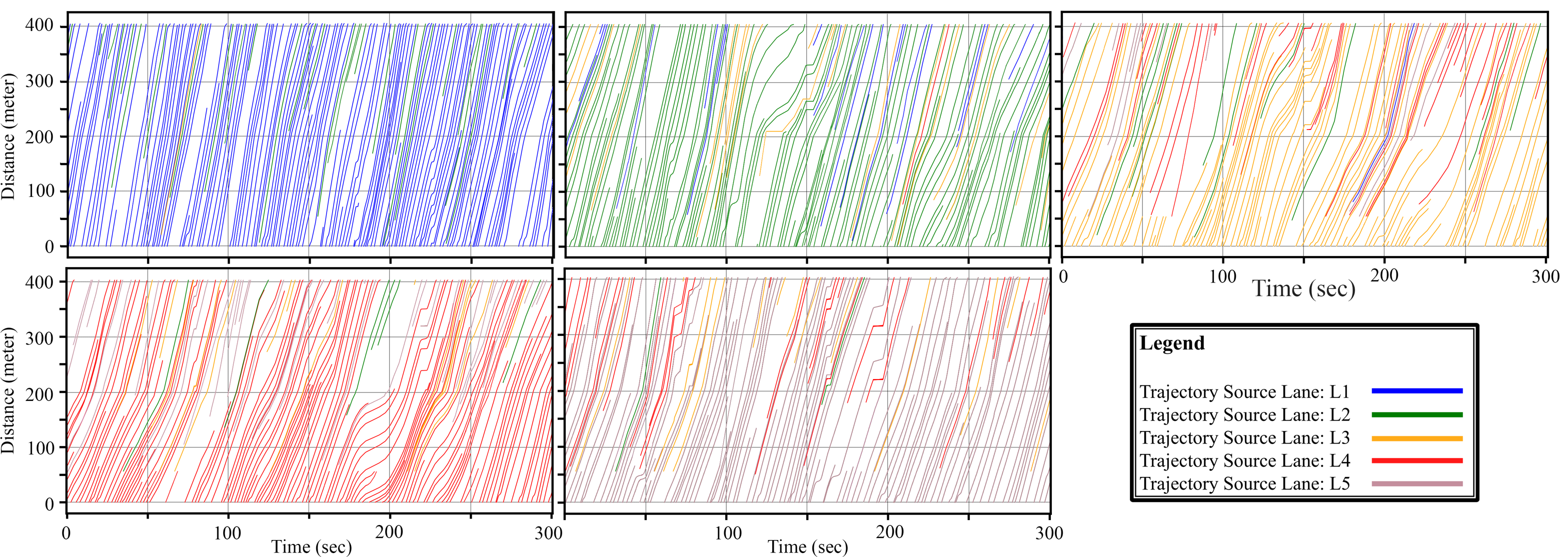
A sample of resulting trajectories: 5 minutes and 400 meters, including lane changes.
As a methodological by-product of the TFC, I developed a segment travel time estimation method based on individual vehicle data from loop detectors. The method enables accurate estimation of lane-based segment travel times between detector stations. The method achieves high accuracy in both uncongested and congested conditions (IEEE 26th ITSC- 2023).
Beyond transportation, the TFC framework demonstrates how continuous, structured trajectories can be reconstructed from sparse, cross-sectional, and partially observed data using probabilistic inference and consistency constraints. At its core, TFC solves a generalized problem: matching fragmented observations across space and time to recover coherent entity-level behavior under uncertainty. This capability is directly transferable to domains such as supply chain tracking, network security event correlation, financial transaction linkage, telecommunications session reconstruction, and sensor fusion in industrial systems, where individual entities must be re-identified and tracked despite incomplete observations. More broadly, the method reflects expertise in large-scale probabilistic matching, uncertainty-aware modeling, spatiotemporal inference, and scalable data engineering, enabling reconstruction of hidden structures from imperfect real-world measurements, an essential capability in any data-intensive industry operating under noise, sparsity, and partial observability.
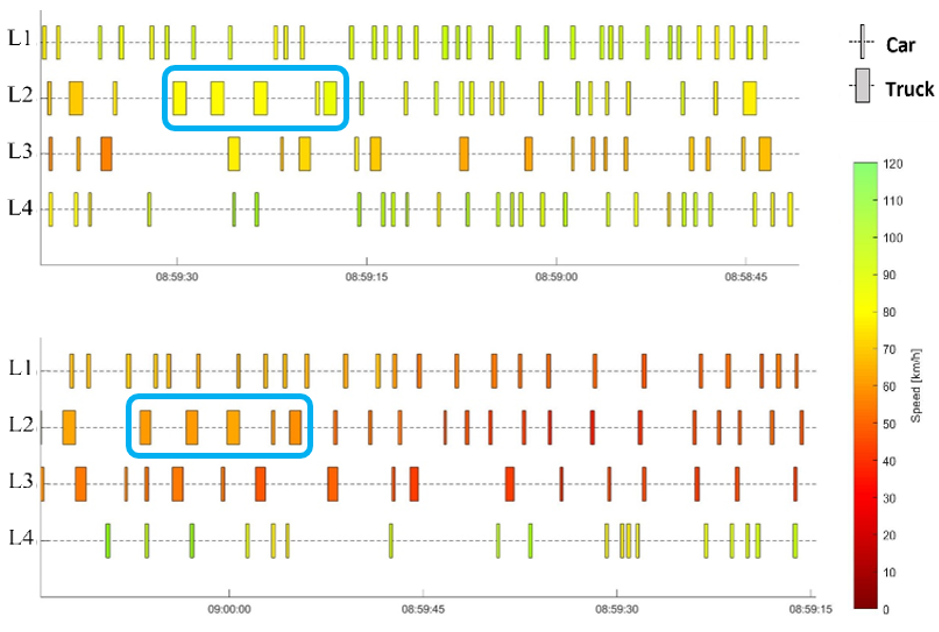
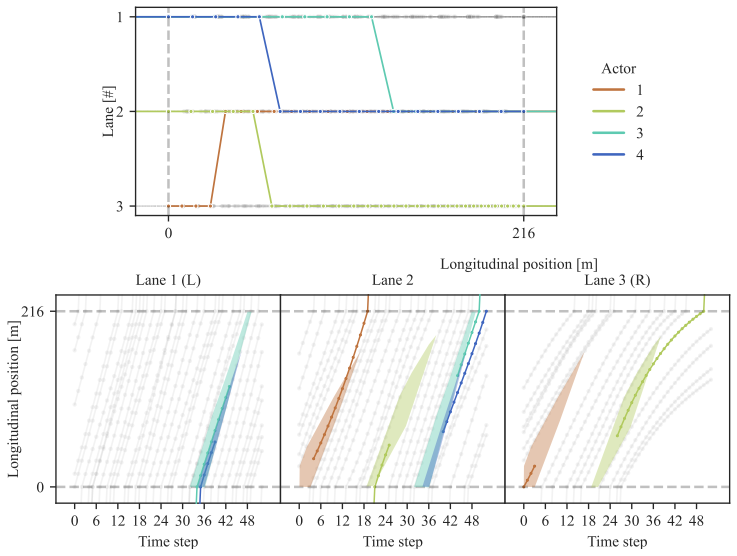
In this project, I supervised and collaborated in the development of a scalable, AI-driven framework for reconstructing lane-level vehicle trajectories using reinforcement learning (RL). The motivation was clear: detailed lane-changing behavior is central to congestion dynamics, capacity drop, and safety risk, yet long, lane-level trajectory datasets are extremely rare and costly to obtain (the same motivation as my other projects like TFC). Building on re-identified loop-detector data, which is actually one of the TFC's outcomes, we reframed trajectory reconstruction as a sequential decision-making problem, where an intelligent agent learns to approximate the location of lane-changing maneuvers while respecting physical feasibility and human driving behavior. The result is a reconstruction pipeline that can be trained on a representative subset and then generalized to large volumes of traffic data, turning sparse infrastructure measurements into behaviorally consistent trajectory datasets.
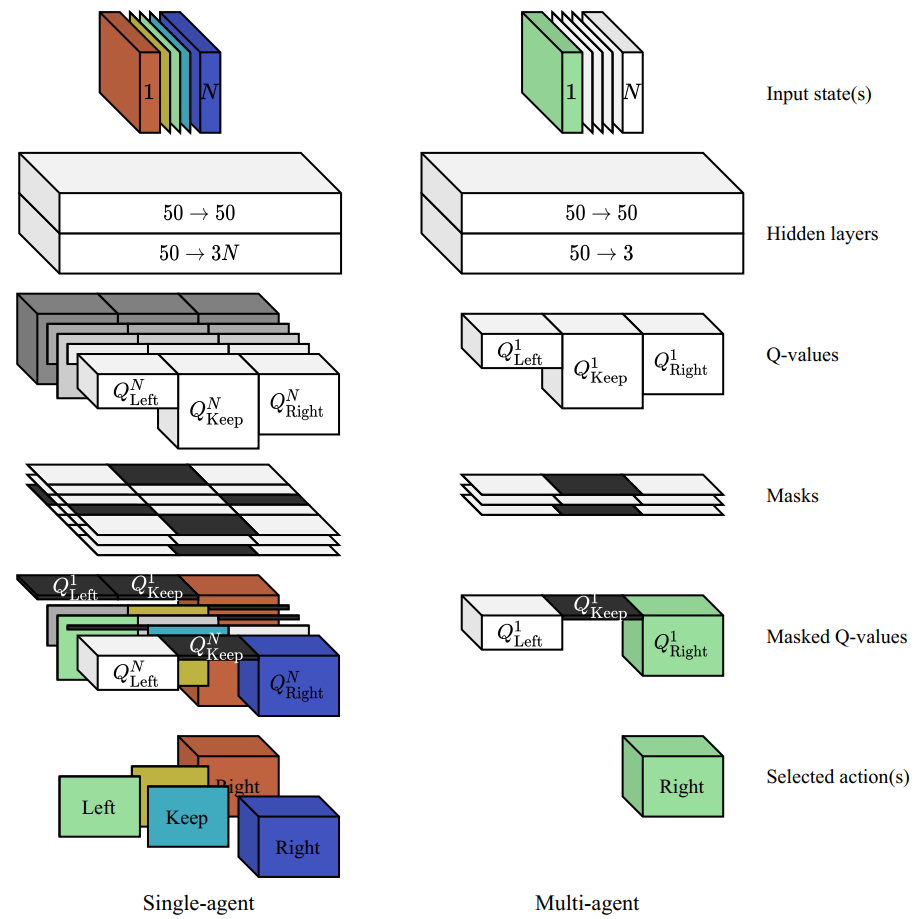
Methodologically, this work demonstrates high-level complex systems modeling and AI expertise by formalizing trajectory reconstruction as a Markov decision process and implementing both single-agent (SARL) and multi-agent (MARL) reinforcement learning formulations. Feasibility conditions were explicitly encoded into the environment through boundary constraints, safety margins (time-to-collision, headway, and relative distance), limits on excessive lane changes, and road-geometry compliance. These were operationalized via carefully designed state representations, structured reward functions, and action masks to ensure behavioral realism and learning stability.
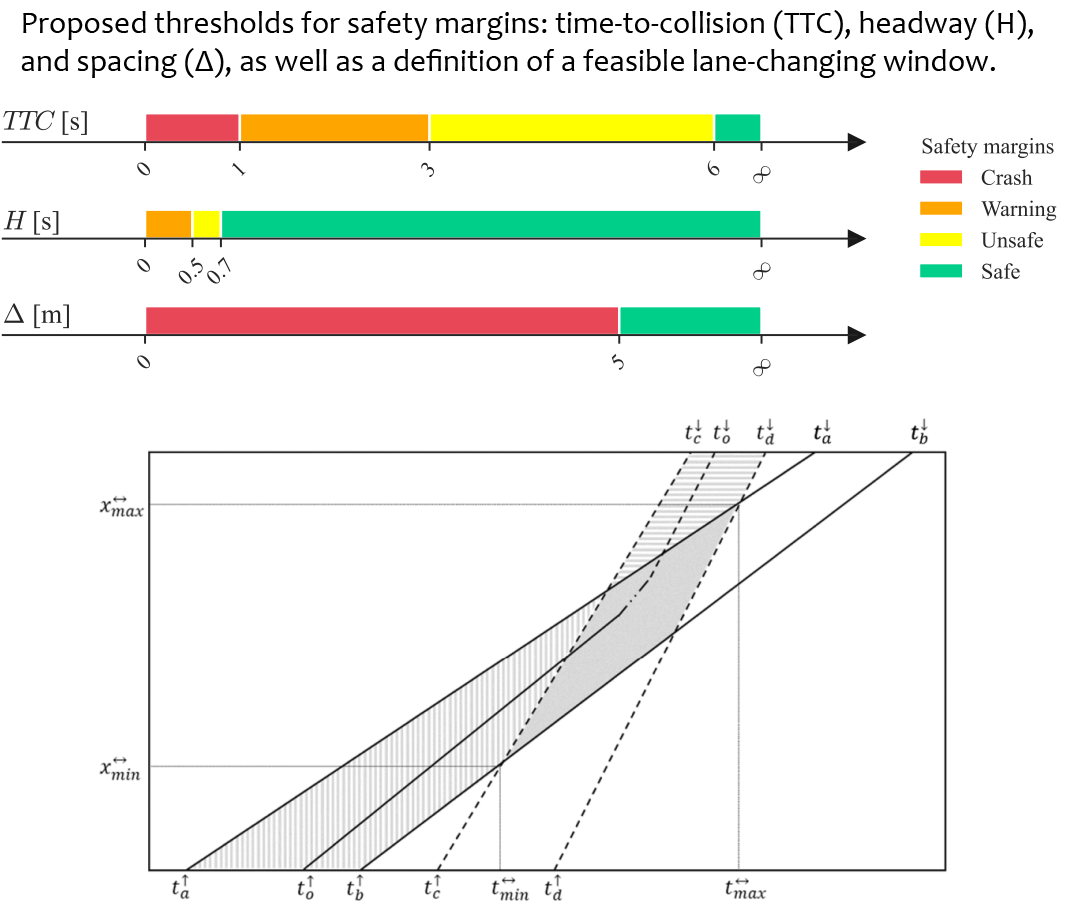
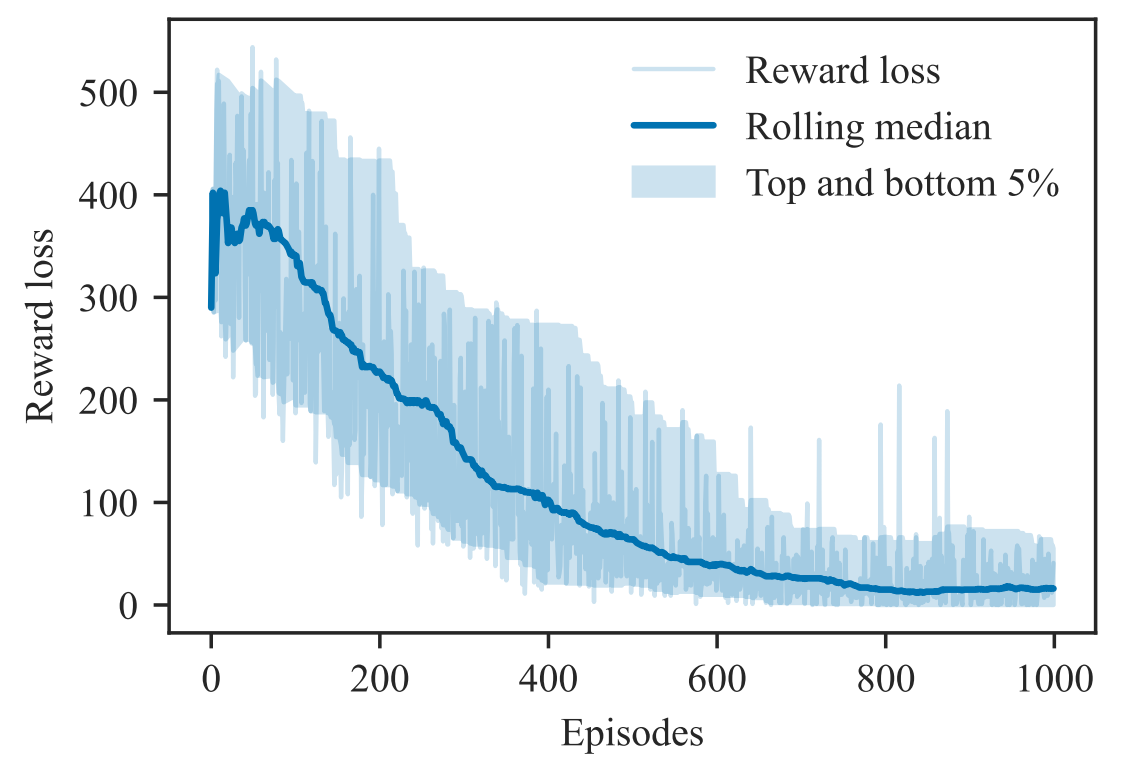
The RL agents were implemented using Deep Q-Networks (DQN), with systematic evaluation of convergence, reward loss decomposition, and generalization across varying traffic samples and actor counts. The MARL formulation demonstrated superior convergence and robustness, especially when scaling to multiple interacting vehicles, and training converged to near-optimal feasibility within a limited number of episodes and modest computational time. This combination of traffic theory, safety modeling, sequential decision processes, and deep learning architecture design reflects an ability to bridge transportation science and advanced AI in a principled and deployable way (Transportation Research Board 103rd Annual Meeting - 2024).
Beyond transportation, this methodology highlights a transferable capability: constructing scalable, generalizable AI pipelines that learn structured behavior under physical and operational constraints. The framework is not limited to motorway lane changes; it can be adapted to domains where synthetic yet behaviorally realistic data are required, such as generating near-miss or crash scenarios for safety analytics, stress-testing autonomous systems, augmenting limited datasets for machine learning, or simulating agent interactions in logistics and robotics. By embedding domain constraints directly into the learning environment, the approach produces data that are both physically plausible and statistically consistent, enabling reliable synthetic data generation in settings where rare events or hazardous scenarios cannot be easily observed in real life. This positions the method as a general AI-based reconstruction and data-generation engine, applicable far beyond the specific traffic segment studied.
This work is an earlier attempt compared to TFC to address a fundamental limitation in traffic operations and safety analysis: the lack of longitudinally continuous vehicle trajectories over extended motorway corridors. In this project, I tackled a practical limitation of floating-car data (FCD): while smartphone-based trajectories are scalable and inexpensive, their lateral accuracy is typically insufficient for lane-level analysis. This matters because many high-impact questions, lane choice, lane changes, weaving dynamics, turbulence, and safety- critical interactions, require knowing which lane a vehicle occupies over time, not just its route. My goal here was to convert widely available smartphone trajectories into lane-identifiable trajectories suitable for microscopic traffic studies, without relying on expensive camera-based trajectory collection.
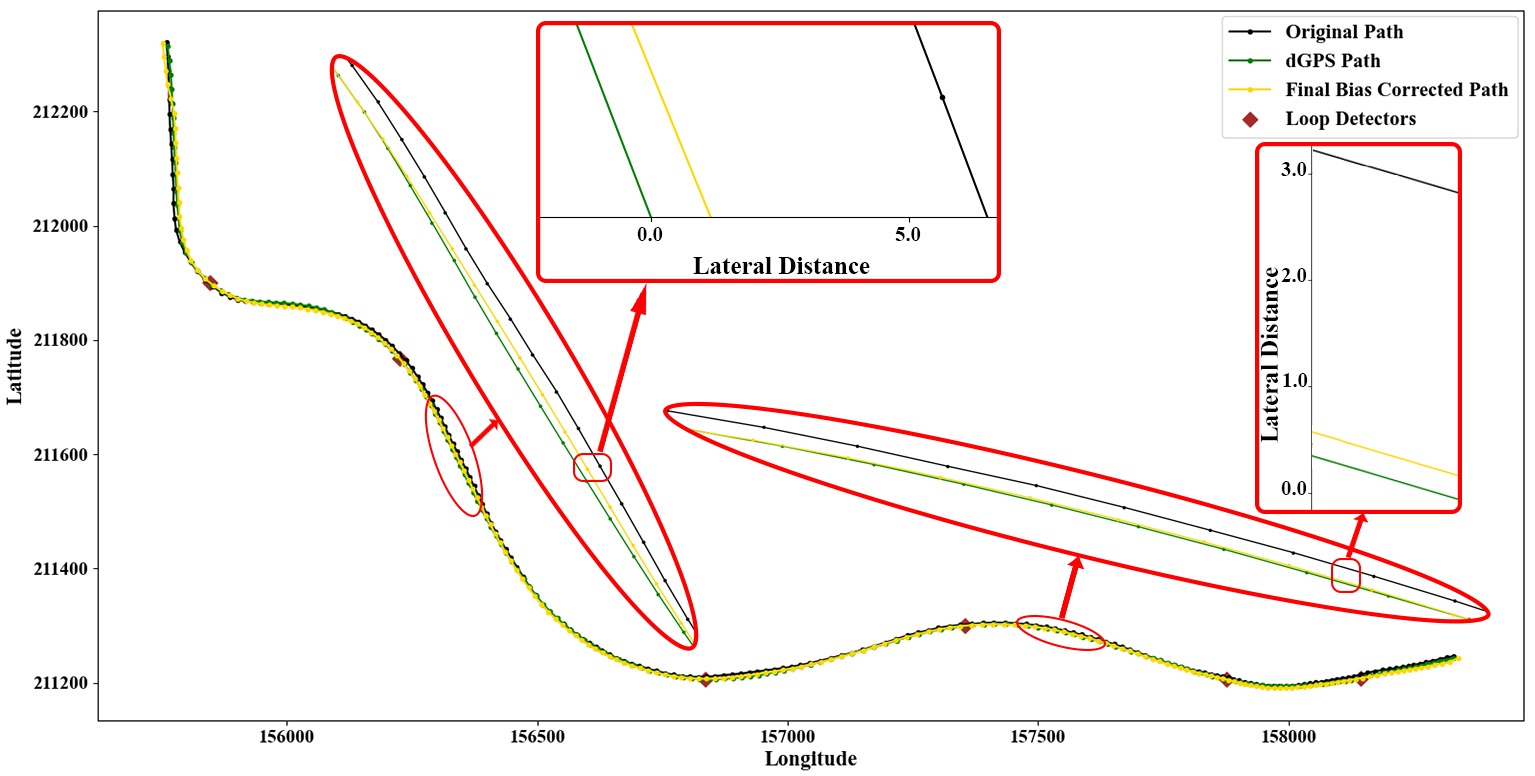
The green line represents the trajectory of a probe vehicle collected using a centimeter-accuracy d-GPS; the other lines represent the same probe vehicle's trajectories collected simultaneously by several smartphones in that car.
In this project, I demonstrated how large-scale, low-cost traffic data streams can be upgraded into lane-level, behavior-aware trajectories suitable for operational decision-making. The contribution is not incremental accuracy improvement, but capability transformation: converting ubiquitous but noisy floating-car data into lane-resolved trajectories that unlock analyses previously restricted to expensive, short-term camera deployments. This enables continuous monitoring of complex motorway segments, such as weaving areas and bottlenecks, where lane usage, lateral maneuvers, and interactions directly drive congestion, capacity loss, and safety risk. The outcome is a scalable, infrastructure-agnostic solution that bridges the gap between strategic network monitoring and microscopic traffic behavior analysis, using data sources that already exist in most operational ecosystems.
Methodologically, this work reflects advanced transport modeling and data-science expertise by framing lane-level trajectory reconstruction as a constrained data-fusion and inference problem, rather than a localization or map-matching task. I designed a pipeline that systematically exploits the complementary strengths of heterogeneous data: continuous but laterally uncertain trajectories are anchored using lane-specific cross-sectional observations, and their lateral bias is corrected through a physically consistent reconstruction process. The approach required careful modeling of measurement uncertainty, vehicle-level consistency, spatiotemporal alignment, and traffic flow structure, while remaining computationally efficient and transferable. The resulting framework does not rely on ad-hoc heuristics; it embeds traffic flow logic, probabilistic matching, and consistency constraints into a deployable algorithm with minimal calibration effort. This combination of theory-driven modeling, statistical reasoning, and large-scale data engineering is what allows the method to perform robustly across traffic regimes and network configurations, and it exemplifies how I approach complex mobility and data science problems: extracting high-resolution behavioral insight from imperfect, real-world data at scale (Transportation Research Part C - 2022).
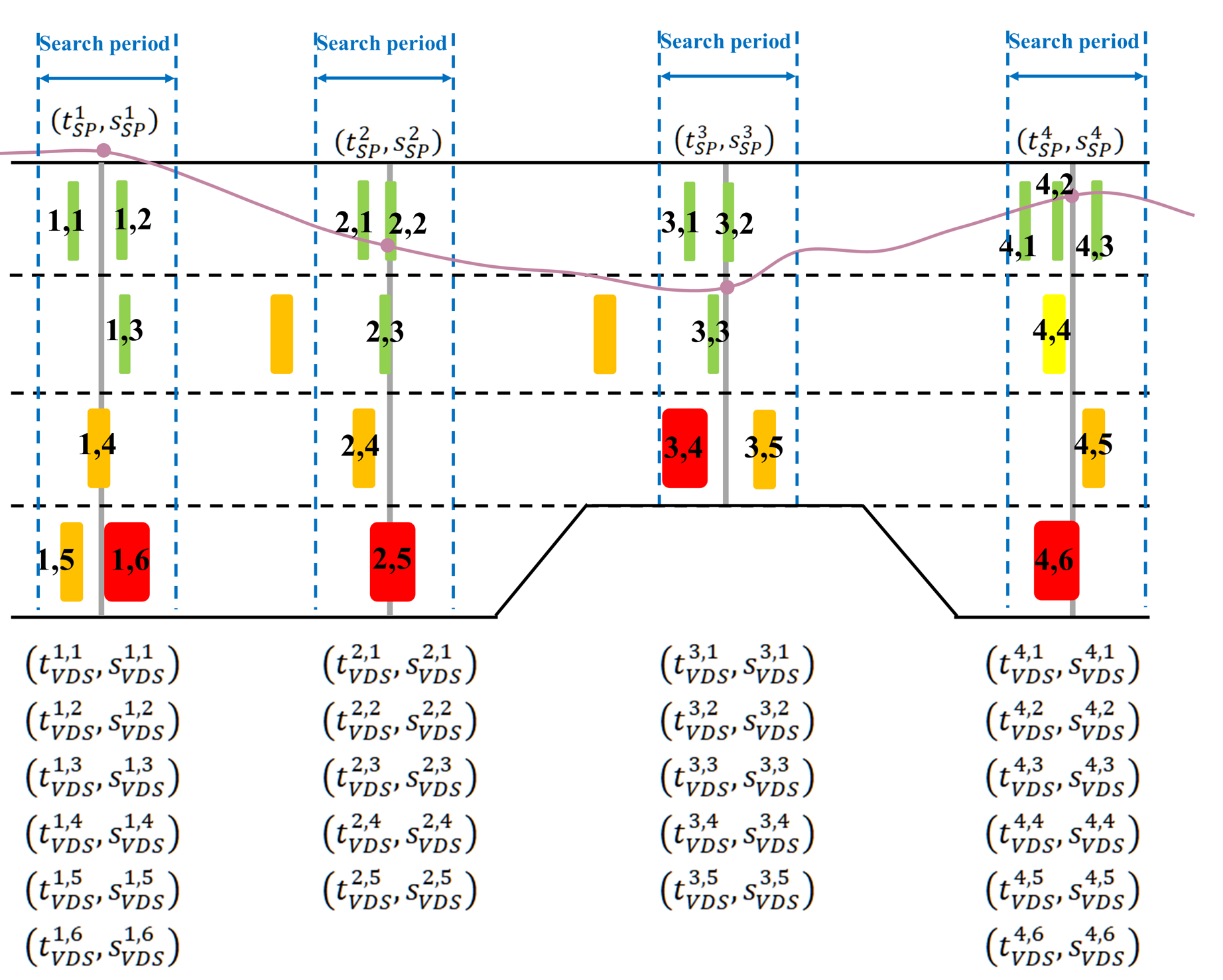
The data fusion logic: Floating-car trajectories are corrected by anchoring them to lane-specific loop-detector detections within time-consistent search windows.
A central requirement for all my data-fusion and trajectory-reconstruction work is the availability of a valid, lane-level routable digital map (RDM). Without such a map, neither longitudinal alignment of sensors nor lateral consistency of vehicle trajectories can be guaranteed. This project was driven by the recognition that existing commercial or open maps are often misaligned, lane-incomplete, or incompatible with real traffic data, especially when the goal is to study lane-level operations and maneuvers. I therefore developed a method to reconstruct lane-level routable maps directly from observed vehicle behavior, ensuring that the resulting map is not only geometrically coherent but also fully consistent with the data streams used for traffic analysis and modeling.
From an industrial perspective, this work transforms low-precision, large-scale GPS trajectory data into a lane-accurate digital asset that supports advanced traffic analytics without reliance on costly mapping campaigns or proprietary HD maps. The resulting maps are routable, lane-consistent, and validated against traffic measurements, making them suitable for applications such as sensor alignment, corridor-level monitoring, lane-based performance analysis, and large-scale behavior modeling. Because the maps are derived from actual driving patterns, they remain robust in complex motorway environments such as merges, diverges, and weaving sections, where traditional density-based or manually curated maps often fail. This enables operators and mobility platforms to deploy lane-level intelligence across wide networks using data they already collect.
Beyond transportation, this method demonstrates how large-scale, noisy, and weakly structured location data can be transformed into high-fidelity digital representations through principled inference rather than direct measurement. The same concepts—network segmentation, statistically robust centerline extraction, density-aware clustering, and outlier detection- are applicable to domains such as logistics, telecommunications, urban analytics, and location-based services, where accurate network representations are essential, but ground truth is incomplete or costly to obtain. More broadly, the project illustrates how combining domain knowledge with statistical modeling enables reliable infrastructure intelligence to be derived from imperfect real-world data at scale.
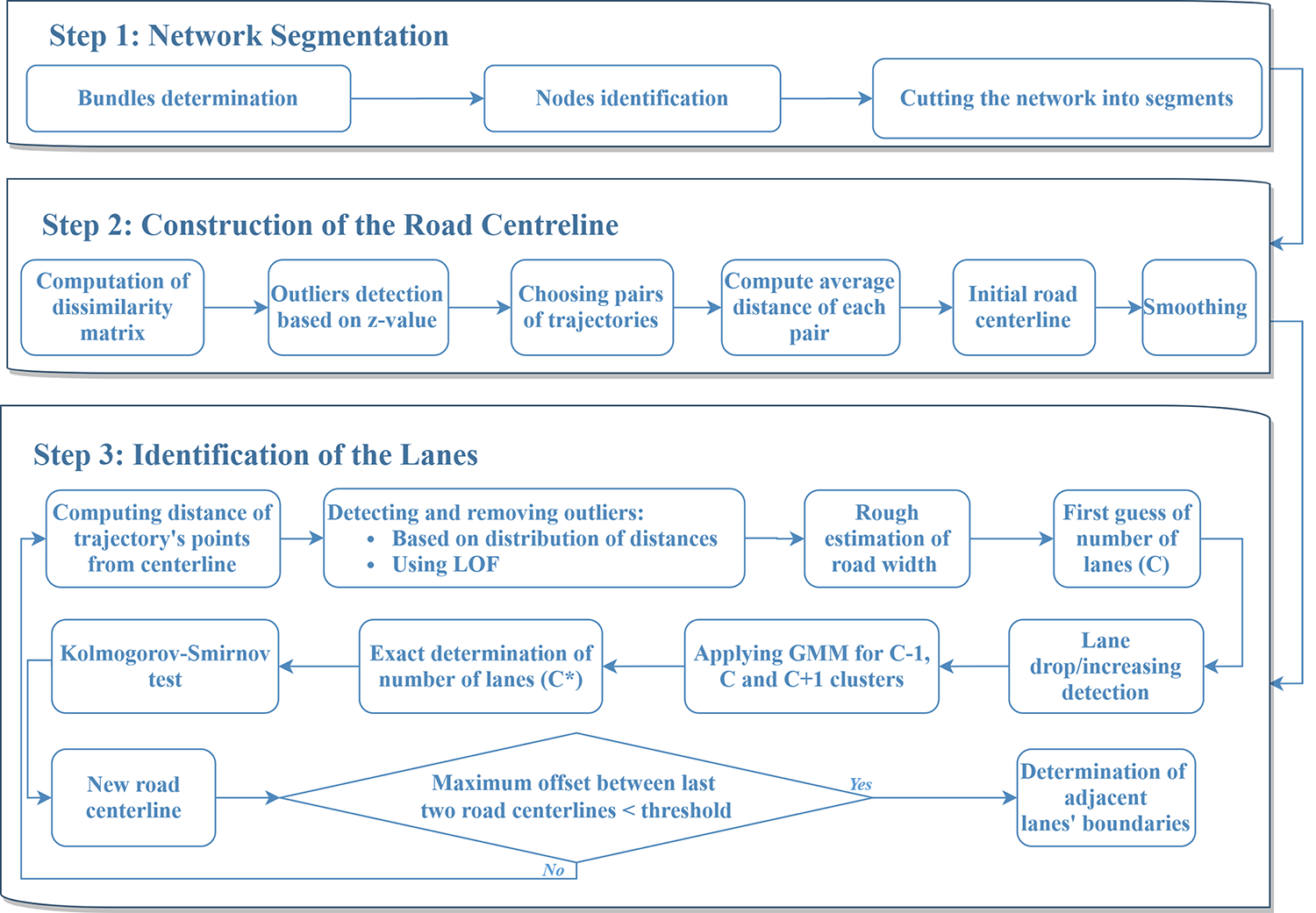
Methodologically, this project demonstrates advanced transport modeling and data-science expertise through a carefully structured three-step algorithm, each addressing a fundamental challenge in lane-level map construction from noisy trajectory data. First, I perform network segmentation by identifying trajectory bundles, detecting network nodes, and cutting the road into coherent segments. This step is critical for handling complex motorway layouts and ensures that downstream modeling operates on topologically meaningful units rather than raw point clouds. Second, I reconstruct a robust road centerline by computing trajectory dissimilarities, filtering outliers using statistical criteria, pairing consistent trajectories, and deriving a smoothed centerline that is resilient to sampling bias and asymmetric traffic usage. Third, I identify lanes through a statistically grounded pipeline: distances to the centerline are analyzed, outliers are removed using distribution-based tests and local outlier factors, the number of lanes is inferred using hypothesis testing and Gaussian Mixture Models, and lane boundaries are determined through iterative refinement until geometric consistency is achieved. This combination of network theory, statistical testing, clustering, and iterative validation reflects a high level of modeling maturity and shows how I translate raw mobility data into reliable, lane-level digital infrastructure that directly supports sensor alignment, data fusion, and advanced traffic behavior analysis (The 11th International Conference on Ambient Systems, Networks and Technologies (ANT) - 2020 and Transportation Research Part C - 2021).
(a) Trajectory bundles; (b) a node where two bundles of trajectories diverge; (c) a node where two bundles of trajectories merge
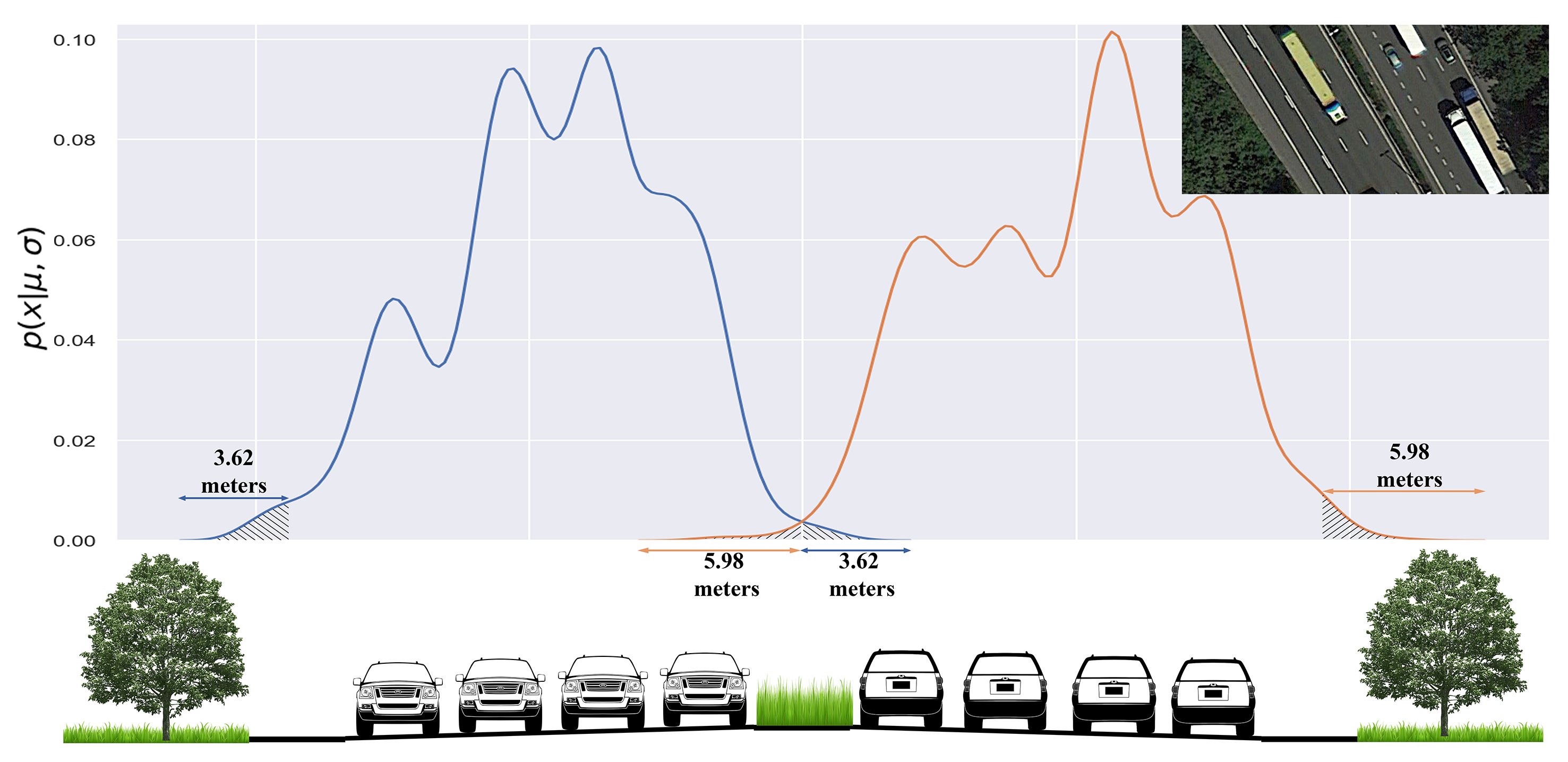
Using distribution of trajectories around identified road centerline to detect outliers. Local Outlier Factor (LOF) is used to identify and remove anomalous trajectory points whose lateral distances to the road centerline are inconsistent with the local density of traffic observations.
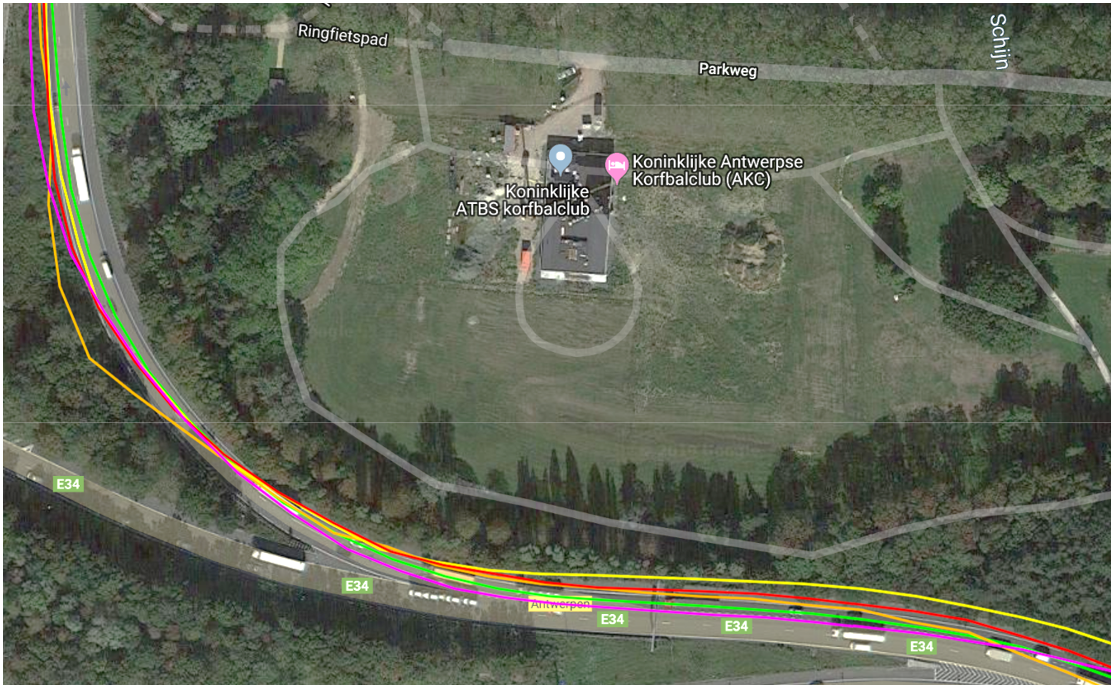
A sample of the reconstructed RDM for a test network around Antwerp, Belgium, is available at link.